原文地址:http://cs231n.github.io/classification/
翻译:Archiew 转载需注明出处
图片分类问题&数据驱动方法引入
目录
引入图片分类、数据驱动方法,数据流
最近邻分类器
K-最近邻分类器
验证集、交叉验证和超参调整
最近邻优缺点
总结
引入图片分类、数据驱动方法,数据流
图片分类问题 就是从一组固定的类别标签中为输入图像分配一个标签。看似简单问题,却包含了计算机视觉的核心问题,有很大的实际应用价值。同时,后面将要讲到的其他计算机视觉任务(eg.目标检测、分割)都可以被简化为图片的分类。
例子 在下面的图像中,图像分类模型接收单个图像并为其分配给4个可能的分类标签{cat,dog,hat,mug}。正如图片所示,我们需要明确:在计算机看来,这幅图片只是一个3维的数据集合——本例中图片表示为248x400x3(248:宽度 400:高度 3:通道数RGB),所以计算机实际上对这副图片的认识是297600个数字——每个数字都是一个0(黑)~255(白)的整数,图片分类任务就是将这写数据转换成一个分类标签,比如:cat。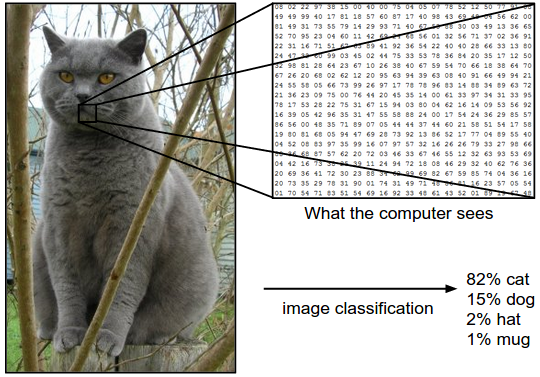
挑战 对人类来说,视觉识别概念相对容易,但对于计算机来说却是一个不小的算法挑战,具体表现为:
- 视角变化(Viewpoint variation)
- 尺度变化(Scale variation)
- 变形(Deformation)
- 遮挡(Occlusion)
- 照明变化(Illumination conditions)
- 背景杂乱(Background clutter)
- 内在变化(Intra-class variation)
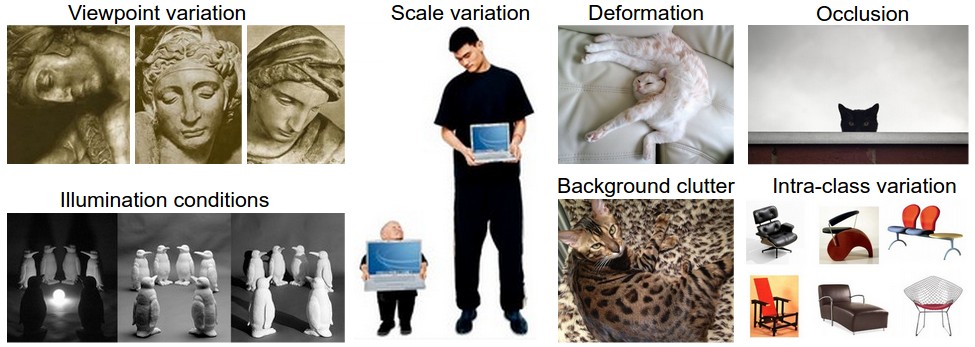
好的图片分类模型需要对这些变化的向量积不变,同时要保证对图片内在变化的敏感性。
数据驱动方法 不像写一个数据排序算法那样明确,识别单个物体的算法并不是很明显,因此我们不会尝试直接在代码中写一个对指定物体的识别算法,而是采用人类学习方式,通过为计算机提供大量的学习数据,然后开发学习算法,从这些提供数据中学习每个分类的‘特征’。这种方法被称为‘数据驱动’,因为它依赖于积累的训练数据集标记图像。以下是这种数据集的实示例: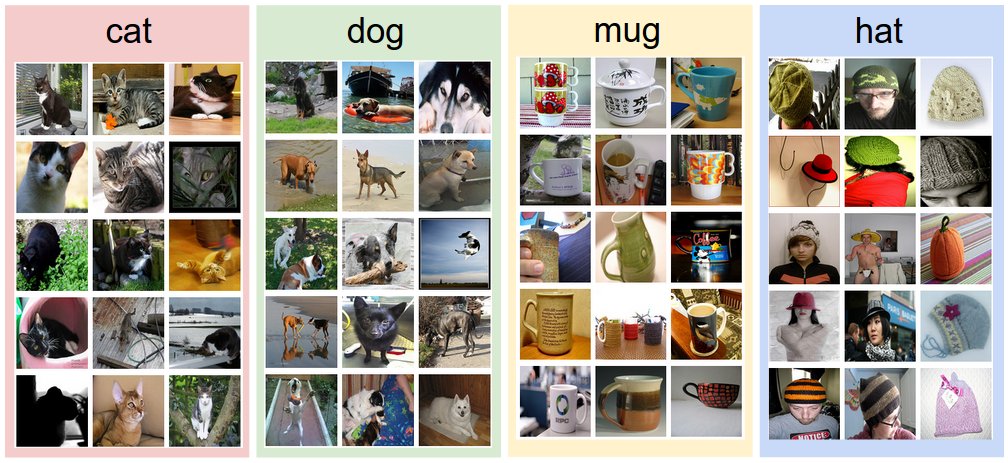
图片分类流 以上,我们了解了图片分类的任务过程,可以总结为如下流程:
- Input输入:包含N个图片的数据集(每个图片对应k个分类标签中的一个),我们将其称为训练集
- Learning学习:图片分类任务是利用上述训练集学习每类图片的‘特征’,我们将其称为训练分类器或者学习模型
- Evalution评估:最后我们通过预测一组新的数据集分类来评估分类器的性能,直观上我们希望预测的标签与图片真实标签(称为真值)相匹配。
最近邻分类器
我们将第一种分类方法成为‘最邻近分类器’(Nearest Neighbor Classifier)。这个分类器和卷积神经网络不相关,并且在实际中几乎用不到,但是它给了我们一个解决图片分类问题的基本思路。
图片分类数据集:CIFAR-10 一个图片分类常用数据集:CIFAR-10 dataset。这个数据集包含了60,000个32x32像素的小图片,每个图片都有一个标签分类(共10个分类:airplane,automobile,bird,etc),这60,000个图片被分为两部分:50,000个训练集和10,000个测试集。下图随机展示了数据集中的部分图片
左:CIFAR-10 dataset示例图片。右:第一列展示了一些测试图片,后边各列展示了根据像素差异显示训练集中的前10个最近邻居。
上图可以看出右边的预测分类仅有3/10的匹配率。
最简单的分类器模型就是对32x32x3数据逐像素点比较差异并求和,换句话说,给定两个图片我们用两个向量\(I_1,I_2\)表示,那么合理的差异比较选择是L1 distance$$d_1(I_1,I_2)=\sum_{p}|I_1^p-I_2^p|$$
下图是这个过程的可视化: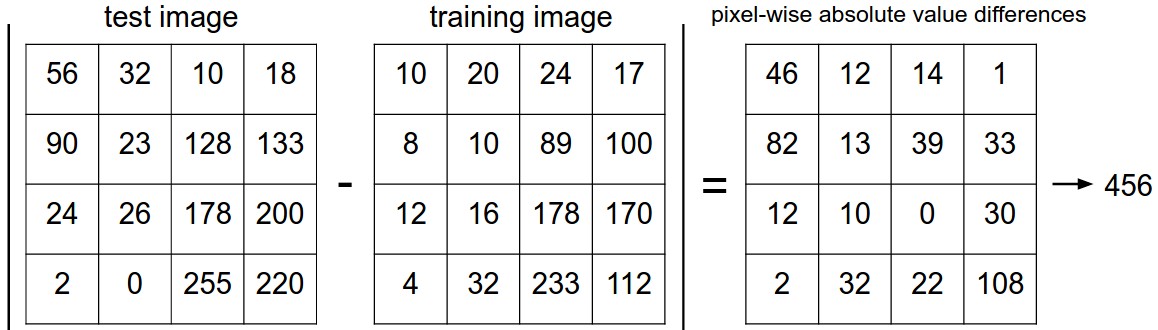
下面会给出这一分类器的代码实现:1
2
3
4
5
6
7
8
9
10
11#加载数据集:training data/labels、test data/labels
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/')
#将三维数据平铺成一维
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) #Xtr_rows变为50000 x 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) #Xte_rows变为10000 x 3072
nn = NearestNeighbor() #创建一个最近邻分类器
nn.train(Xtr_rows, Ytr) #在训练集(含标签)上训练分类器
Yte_predict = nn.predict(Xte_rows) #在测试集上预测标签
#打印预测分类准确度(取平均值)
print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )
准确度accuracy,经常作为一个评估标准来评价预测结果正确性。上面的代码中关键的是训练函数train(X,y)和预测函数predict(X),最重要的是分类器本身的实现,下面的代码实现了一个具有L1 distane的简单的最近邻分类器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26import numpy as np
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X是NxD的训练集(其中每行代表一个数据样本). y是大小为N的一维数据 """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X是NxD的测试集(每行代表一个我们需要预测标签的样本数据) """
num_test = X.shape[0]
# 确保输入输出数据类型匹配
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# 遍历所有测试集样本数据
for i in xrange(num_test):
# 根据L1 distance找出和第i个测试图像最近邻的训练图片
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # 获取最小差异图像的索引值
Ypred[i] = self.ytr[min_index] # 预测最近邻样本的标签
return Ypred
上述代码实现了在CIFAR-10上38.6%的准确度,相对于人类近94%或者最先进(state-of-the-art)的卷积神经网络近95%(最新排行)的准确度来说,这个结果可谓悲观。
距离的选择 除上述L1 distance之外,还有许多其他计算向量之间距离的方法,另一个常用的计算方法是‘L2 distance’,计算公式如下所示:
$$d_2(I_1-I_2)=\sqrt{\sum_p(I_1^p-I_2^p)^2}$$
换句话说,L1 distance计算的是像素差,而L2 distance计算的是像素差的平方和的开方,我们用一行代码来替换上述计算距离的代码1
distances = np.sqrt(np.square(self.Xtr-X[i,:]), axis=1)
上述代码中的np.sqrt在实际操作中一般被略去,因为开方函数是一个单调函数。也就是说,它仅仅改变了距离的绝对尺度但保留了距离排序,因此是无关紧要的。用这种方法计算距离得到了35.4%的预测准确度(略低于用L1 distance的结果)
L1 VS L2 考虑这两者之间的差异会很有趣。实际上在涉及到两向量差异时L2 distance比L1 distance更unforgiving,也就是说相对于大的差异来说L2 distance更偏向于中等大小的差异。L1和L2 distance(等效于一对图片差异的L1/L2范数???)时p范数中最常用的特殊情况。
K-最近邻分类器
注意到上述预测只是利用了给定图片最近邻图像的标签。实际上更为常用且表现更好的方法是使用我们称之为‘k-Nearest Neighbor Classifier’(K-最近邻分类器)的分类器。其原理很简单:我们在训练集中寻找与测试图片近邻的top k个图片而不是之前的金庸一个最近邻图片来做标签预测。实际上,当k=1时就是上述最近邻分类器。直观上k值越大,分类器对于异常值平滑效果越好。
虽然k-最近邻分类器优于最近分类器,但是还有一个k值的选择问题。
验证集、交叉验证和超参调整
k-最近邻分类器需要设定k值,如何确定最优k值?此外,还有不同的距离计算方法,如上所示的L1范式和L2范式,甚至我们未曾考虑的点积计算等。这些多样选择我们称之为超参数,在许多机器学习算法的设计中这是很常见的。通常情况下,超参数值的确定并不明显。
你可能想到通过尝试多个参数值来寻找出最优值。这确实是个好想法,并且我们也确实打算这样做,但是我们必须对此持谨慎的态度!实际上,我们不能使用测试集来调整超参数。在设计机器学习算法时我们必须时刻将测试集视为一个宝贵的资源,理想情况下我们只会在最后阶段运用它。否则会出现在测试集上表现良好的超参数值在部署模型到新预测图片时性能显著下降的问题。这个问题我们称之为对测试集的overfit(过拟合)。只在最后阶段使用测试集会是衡量我们的分类器模型泛化的一个好的代理。
测试集上的评估只能使用一次,在最后阶段
幸运的是,有一个好方法来调整超参数而不触碰到测试集。具体做法为:将一个训练集分割为两部分,一个训练集和一个较小样本的验证集。以CIFAR-10为例,我们可以将样本数据集分为:包含49,000个图片的训练集和包含1,000个图片的验证集,验证集本质上是作为伪测试集用来调整超参数的。
下面给出了具体在CIFAR-10上的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 假设我们已经得到了Xtr_rows, Ytr, Xte_rows, Yte
# Xtr_rows:50,000 x 3072
Xval_rows = Xtr_rows[:1000, :] # 取前1000样本做验证集
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # 取后49000样本做训练集
Ytr = Ytr[1000:]
# 寻找在出验证集上的最优超参数
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# 选用一系列k值并在验证集上进行评估
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
# 跟踪在验证集上的表现
validation_accuracies.append((k, acc))
最后,我们可以绘制出每次验证集上的准确度图并找出最优k值,再将此k值带入分类器并在测试集上做最终评估。
将你的训练集分割成训练集和验证集,使用验证集调整超参数,最后在测试集上做一次评估并输出分类器性能
交叉验证 如果训练集规模很小,更多的是用一种复杂的技术来调整超参数,我们称之为cross-validation(交叉验证)。还以先前例子为例,这次我们不是随意地将训练集的前1000个样本作验证集剩下的做训练集,我们可以通过迭代不同的验证集并平衡其性能以获得一种更好且噪声更小的估计k的特定值。例如,在5-折交叉验证中,我们将训练集分割成5等份,用其中的4个作为训练集剩1个做验证集,得到一个评估性能,然后迭代地分别取不同的小份做验证集,这样可以得到5个评估性能值(准确度),最后取平均值。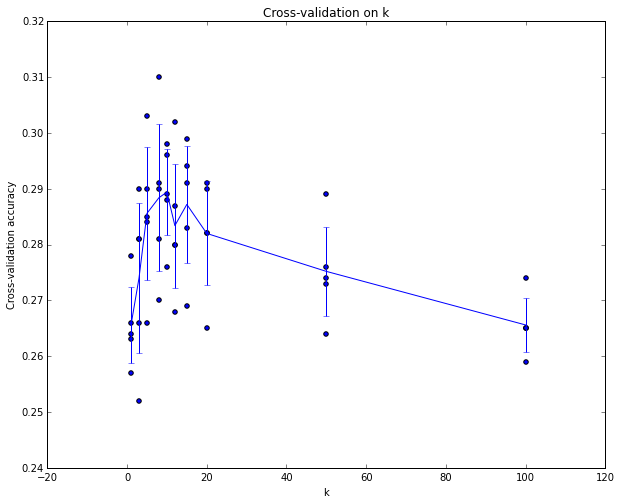
实践 实际操作时人们会更倾向于避免交叉验证而使用单一验证,因为交叉验证会消耗大量的计算资源。人们一般会使用训练集的50%-90%作为训练剩下的做验证,而这取决于多个因素:如果超参数数量很多,你可能更倾向于分割出更大的验证集;而如果验证集中的样本数量很少(几百个),最好是用交叉验证。常用的折数一般为3-折,5-折,10-折。
最近邻优缺点
考量最邻近分类器的优缺点是有必要的。很明显,一个优势是它很简单且易于理解,除此之外分类器无需花费时间去训练,但是我们的时间花费在了预测上,因为预测需要比较测试图片和每一个训练样本的差异。这是backwards(倒退的),因为实际上我们更关注的是预测时的时间效率。实际上随后讲到的深度神经网络将这个权衡移到了另一个极端:在训练时花费大量资源(运算、时间),而在训练结束它会非常快地对测试图片进行分类预测。这种操作模式在实际运用中更可取。
另外,对于最近邻分类器的计算复杂度是另一个活跃的研究点,并且有一些近似最近邻(ANN)算法和库可以加速数据集中最近邻的查找(eg. FLANN)。这些算法允许人们在查找期间利用空间/时间复杂度来权衡最近邻查找的正确性,并且通常依赖于涉及构建kdtree或运行k均值算法的预处理/索引阶段。
最近邻分类器在某些情况下会是一个很好的选择(尤其是低维度数据),但是在实际运用中很少去用作分类设置,其中一个问题是图片是高维物体(包含了大量像素数据),而且高维空间的距离可能非常违反直观感觉。下图说明了我们上面开发的基于像素的L2相似度与感知相似度非常不同的点:
在高维数据(尤其是图片)上基于像素的距离可能非常不直观。原图(左)和其他三幅图片在L2像素距离上有很大差异。很明显,像素距离和感知或语义相似并不一致。
下面给出了更多可视化图片方便理解使用图片见的像素差异并不能很好地胜任分类问题。运用可视化技术(t-SNE)将CIFAR-10中的图片展示在二维面上,一边保留他们的(局部)成对距离。在可视化过程中距离最近的图片被认为是最相近的(根据上述L2像素距离来讲)。![]()
实际上,上述图片相近的图片更多的是在背景色彩上具有相似性而不是语义上的相似性。理想情况下我们希望所有图片会形成10个聚类,因此相同类的图像彼此相邻近而忽视无关特征和变化(如背景)。但是要获得这种属性,我们必须超越原始像素。
总结
- 引入图片分类问题。给定一个带有单个分类标签的图片集,需要预测新的测试集中图片的分类并计算预测准确度。
- 引入了简单分类器最近邻分类器(Nearest Neighbor classifier)。认识到与分类器相关的多个超参数(k,distance计算类型等),并且它们的选择并不明显
- 认识到设置超参数的正确方法是分割训练集为两部分:训练集和伪测试集(验证集),尝试多个不同的超参数值并且选出在验证集上表现最好的那个值
- 如果缺少训练集,我们讨论了一个交叉验证(cross-validation),这会帮助我们减少估计最优超参数值的噪声
- 一旦寻找到最优超参数值,我们将其固定下来并在真实测试集上做单次评估
- 认识到最近邻分类器在CIFAR-10上可以获得约40%的准确度,实现起来会很简单但是需要存储所有训练集并且在测试集上评估会很耗时
- 最后,我们认识到在原始像素上计算L1和L2距离并不能胜任分类工作,因为这种距离更多地和图片背景、色彩分布相关而不是图片的语义内容。
下一讲,着手处理本节中的挑战并且最终达到90%的准确度,让我们在完成学习之后完全抛弃训练集们,并且实现在1ms之内预测图片。