简易信息聚合(Really Simple Syndication, RSS)是一种基于XML标准在互联网上被广泛采用的内容包装和投递协议。RSS允许用户以计算机可读的标准格式来获取(订阅)网站内容更新。相对于直接访问网站,使用Rss订阅能更快地
获取网站内容更新。RSS具有以下几个特点:
- 来源多样的个性化“聚合”特性。
- 信息发布的时效、低成本特性。
- 无“垃圾”信息、便利的本地内容管理特性。
本文给出用python实现将RSS转换为电子书并推送给kindle的方法,可以自主方便地订阅自己感兴趣的RSS(类似狗耳朵、Kindle4RSS之类)。
一、获取并解析RSS内容
对于RSS内容的获取解析,python有专门的第三方库可以实现:feedparser。所以我们首先安装feedparser:pip install feedparser
然后来测试一下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96# -*- coding: utf-8 -*-
"""
-------------------------------------------------
Version: Python3.6
-------------------------------------------------
"""
import feedparser
contents = feedparser.parse('http://news.qq.com/newsgn/RSS_newsgn.xml')
print(contents)
# 打印如下:
{
'feed': {
'title': '新闻国内',
'title_detail': {
'type': 'text/plain',
'language': None,
'base': 'http://news.qq.com/newsgn/RSS_newsgn.xml',
'value': '新闻国内'
},
'image': {
'title': '新闻国内',
'title_detail': {
'type': 'text/plain',
'language': None,
'base': 'http://news.qq.com/newsgn/RSS_newsgn.xml',
'value': '新闻国内'
},
'links': [{
'rel': 'alternate',
'type': 'text/html',
'href': 'http://news.qq.com'
}],
'link': 'http://news.qq.com',
'href': 'http://mat1.qq.com/news/RSS/logo_news.gif'
},
'subtitle': '新闻国内',
'subtitle_detail': {
'type': 'text/html',
'language': None,
'base': 'http://news.qq.com/newsgn/RSS_newsgn.xml',
'value': '新闻国内'
},
'links': [{
'rel': 'alternate',
'type': 'text/html',
'href': 'http://news.qq.com/china_index.shtml'
}],
'link': 'http://news.qq.com/china_index.shtml',
'rights': 'Copyright 1998 - 2005 TENCENT Inc. All Rights Reserved',
'rights_detail': {
'type': 'text/plain',
'language': None,
'base': 'http://news.qq.com/newsgn/RSS_newsgn.xml',
'value': 'Copyright 1998 - 2005 TENCENT Inc. All Rights Reserved'
},
'language': 'zh-cn',
'generator_detail': {
'name': 'www.qq.com'
},
'generator': 'www.qq.com'
},
'entries': [{
'title': '钳工张学海:从0.05毫米的合格走向0.01毫米的卓越',
'title_detail': {
'type': 'text/plain',
'language': None,
'base': 'http://news.qq.com/newsgn/RSS_newsgn.xml',
'value': '钳工张学海:从0.05毫米的合格走向0.01毫米的卓越'
},
'links': [{
'rel': 'alternate',
'type': 'text/html',
'href': 'http://news.qq.com/a/20180422/006743.htm'
}],
'link': 'http://news.qq.com/a/20180422/006743.htm',
'authors': [{
'name': 'www.qq.com'
}],
'author': 'www.qq.com',
'author_detail': {
'name': 'www.qq.com'
},
'tags': [],
'published': '2018-04-22 11:32:50',
'published_parsed': time.struct_time(tm_year = 2018, tm_mon = 4, tm_mday = 22, tm_hour = 11, tm_min = 32, tm_sec = 50, tm_wday = 6, tm_yday = 112, tm_isdst = 0),
'comments': '',
'summary': '......',
'summary_detail': {
'type': 'text/html',
'language': None,
'base': 'http://news.qq.com/newsgn/RSS_newsgn.xml',
'value': '......'
}
},
......
可以看出解析结果是json类型,我们可以从中提取所需信息(contents[‘feed’][‘title’],contents[‘entries’]),其中contents[‘entries’]是个list类型,里面包含多条内容,我们逐条提取即可。
二、将提取信息制作成电子书
这里用到的是Amazon提供的kindle电子书制作工具:kindlegen
KindleGen 是一个免费的命令行工具,也是亚马逊唯一官方支持的文件转换工具,可通过它把 HTML、XHTML 或 IDPF 2.0 格式(带有 XML.opf 描述文件的 HTML 内容文件)的源文件创建为 Kindle 电子图书。高级用户可以使用命令行工具将 EPUB/HTML 转换为 Kindle 电子书。 您可以在 Windows、Mac 和 Linux 平台上使用此界面。此工具可用于自动批量转换。
1.kindlegen下载地址
2.kindlegen用法
3.制作电子书相关
4.kindlegen官方指南
这里讲几个关键,要想使用kindlegen生成电子书,需要提供几个必要文件:.html,.opf,.ncx,.jpg等,这些文件作用如下(参考3):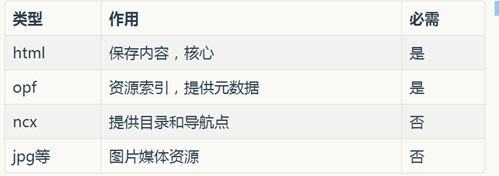
.html中用到的媒体文件(图片、音频等)必须保存在本地,kindlegen不负责对他们进行渲染下载。
下面简单介绍一下这几个文件:
.opf
.opf是我们用kindlegen生成电子书时需要直接提供的文件,是电子书的资源索引文件,提供元数据,相当于对电子书用到的资源的一个声明:电子书用到的.html,.jpg等都需要在.opf中事先定义好才能用。.opf格式如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26<package xmlns="http://www.idpf.org/2007/opf" version="2.0" unique-identifier="BookId">
<metadata xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:opf="http://www.idpf.org/2007/opf">
<dc:title>电子书标题</dc:title>
<dc:language>zh-cn</dc:language>
</metadata>
<manifest>
<!-- table of contents [mandatory] -->
<item href="toc.ncx" media-type="application/x-dtbncx+xml" id="ncx"/>
<item id="tochtml" media-type="application/xhtml+xml" href="toc.html"/>
<item id="item0" media-type="application/xhtml+xml" href="Artical-1277621753.html"/>
...
<!--下面是图片-->
<item id="0.368541311142" media-type="image/jpg" href="Images/-1720404282.jpg"/>
</manifest>
<spine toc="desertfire">
<!-- 下面描述了KG生成电子书后文本的顺序(idref必须与上述资源id对应) -->
<itemref idref="ncx"/>
<itemref idref="tochtml"/>
<itemref idref="item0"/>
</spine>
<guide>
<reference type="toc" title="Table of Contents" href="toc.html"></reference>
<reference type="text" title="Welcome" href="toc.html"></reference>
</guide>
</package>
熟悉.html的不难理解这个格式,关于更多详细信息,可以参考这里,我们需要修改的有:<dc:title>xxx</dc:title>、<item id="xxx" .../>、<item idref="xxx"/>,三者作用分别是: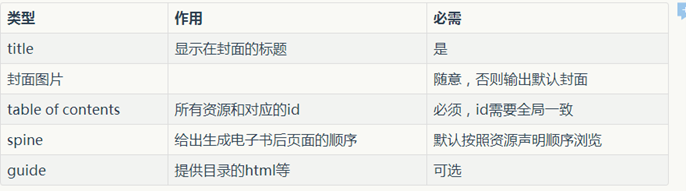
.ncx
.ncx是制作电子书目录的文件,这是一个xml文件,该标准由DAISY Consortium发布(参见http://www.daisy.org)。.ncx文件格式如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36<?xml version="1.0" encoding="utf-8"?>
<ncx version="2005-1" xmlns="http://www.daisy.org/z3986/2005/ncx/">
<head>
<!-- The following four metadata items are required for all NCX documents, including those conforming to the relaxed constraints of OPS 2.0 -->
<meta name="dtb:uid" content="xxx"/>
<meta name="dtb:depth" content="2"/>
<meta content="RSS2kindle (by Archiew)" name="dtb:generator"/>
<meta name="dtb:totalPageCount" content="0"/>
<meta name="dtb:maxPageNumber" content="0"/>
<meta name="right" content="该文档由www.kindle.archiew.top生成。www.kindle.archiew.top为在线免费电子书分享平台,内容完全来自网络,仅供个人交流与学习使用,不得用于任何商业用途。"/>
</head>
<docTitle>
<text>xxx</text>
</docTitle>
<docAuthor>
<text>Archiew</text>
</docAuthor>
<navMap>
<navPoint id="navpoint-1" playOrder="1">
<navLabel>
<text>目录</text>
</navLabel>
<content src="tableOfContents.html" />
</navPoint>
<navPoint id="navpoint-2" playOrder="2">
<navLabel>
<text>xxx</text>
</navLabel>
<content src="xxx" />
</navPoint>
</navMap>
</ncx>
关于更多详细信息,可以参考这里,我们需要修改的有:<meta name="dtb:uid" content="xxx"/>、<docTitle />、<navMap />,三者作用分别是:电子书uid(每本书uid不能一样)、书籍标题、目录
.html
分为目录html(toc.html)和正文html(chapter.html)
目录html用于生成电子书目录,格式如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="zh-CN">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<link rel="stylesheet" type="text/css" href="main.css"/>
<title>电子书标题</title>
</head>
<body>
<div>
<h1>目录标题</h1>
<p class="center">Made by <a href="http://www.kindle.archiew.top">书舟网</a></p>
</div>
<p></p>
<div>
<h1 class="category">目录</h1>
<p class="chapter"><span><a href="章节html链接"><span></span><span>章节标题</span></a></span></p>
</div>
<div>
<br>
<hr />
<p>该书籍由网页内容生成,版权归原网站所有,仅供学习交流之用,请在下载后24小时内自行删除!</p>
<p>书舟网-免费电子书分享平台(www.kindle.archiew.top)</p>
</div>
</body>
</html>
正文html用于生成电子书正文内容,格式可以随意发挥
用kindlegen生成电子书过程为,首先根据.opf文件确定电子书需要的所有资源文件(主要是.ncx、目录html、正文html、媒体资源等)以及电子书内容的排列顺序(取决于.opf中
以上就是用kindlegen生成电子书的详细介绍,但是我们不可能手动地一个个生成所需文件,这时就需要用到模板引擎,python下推荐Jinja2 ,有了模板引擎,我们只需提供几个模板文件,然后通过Jinja2将解析出来的RSS内容填充到模板生成所需要的文件。最后用kindlegen命令kindlegen xxx.opf就能生成所需的电子书了。
三、将电子书推送到kindle
上面我们生成的电子书,通过邮件发送到kindle邮箱即可完成推送
*注意:
1、由于各网站生成RSS工具不一样,所以用feedparser解析出来的内容可能不太一样(不会有很大差别);
2、有的RSS只提供内容摘要,如果需要获得全文输出,需要自行爬取全文或者用一些全文RSS输出工具如Full RSS、FeedEx
3、对于含图片的RSS,由于kindlegen不负责远程渲染媒体文件,所以需要自行爬取图片到本地